How important are underlying assumptions?
Let's suppose that you are asked to guess the age of a person based on nothing but his height. You are told that the age of the person is either six years old or twenty-six. You further know that the mean height of the six-year-olds is 48 inches and the mean height of the twenty-six-year-olds is 68 inches.
What you would reasonably do is calculate the midpoint between the two heights, 58 inches, and classify anyone with a height above 58 inches as an adult, and anyone with a height below 58 inches as a child.
Of course, you know perfectly well that not all adults are taller that 58 inches, nor are all children shorter than 58 inches. So your decision rule carries with it some probablility of error.
 This error is calculable, generically, from the graph on the right. Shown are two normal distributions: p0(x) is the distribution of children's heights, with mean μ0 = 48 inches, p1(x) is the distribution of adult's heights, with mean μ1 = 68 inches. Those with training in statistics will recognize these graphs as probability density functions; those without it can think of them as plots of the relative number of people in each population (on the vertical axis) as a function of a particular height (on the horizontal axis). Thus, most children's heights are clustered around their average height, μ0, where the curve p0(x) is at its maximum value. Yet some children are taller, and a diminishingly small percentage of children are much taller. The inverse would be true for the adult population.
This error is calculable, generically, from the graph on the right. Shown are two normal distributions: p0(x) is the distribution of children's heights, with mean μ0 = 48 inches, p1(x) is the distribution of adult's heights, with mean μ1 = 68 inches. Those with training in statistics will recognize these graphs as probability density functions; those without it can think of them as plots of the relative number of people in each population (on the vertical axis) as a function of a particular height (on the horizontal axis). Thus, most children's heights are clustered around their average height, μ0, where the curve p0(x) is at its maximum value. Yet some children are taller, and a diminishingly small percentage of children are much taller. The inverse would be true for the adult population.
The decision point, δ = 58 inches, is the point where the curves cross, and the total probability of error is:

For those without a calculus background, all this is saying is that we are adding up all the children with heights above 58 inches and all the adults with heights below 58 inches, and say in advance that these will be mis-classified by our decision rule δ. But we can also see that δ is still at its optimum value; moving it to the right, for instance, will slightly diminish the number of children mis-classified as adults, but dramatically increase the number of adults mis-classified as children.
However, we make three critical assumptions to choose 58 inches as our decision point.
Assumption 1: the distributions are the same shape.
Since the effect of this first assumption is fairly easy to illustrate, let's redraw the distributions given the mean values listed above. Fellow bitheads will recognize the work of Matlab, vice the MS Word drawing tool used before.
 Now let's make the distribution for the adults twice as wide as for the children:
Now let's make the distribution for the adults twice as wide as for the children:
 Notice the effect on the crossover point. If the distribution of heights is greater for adults than for children (as it almost certain is), the cross-over point moves from 58 inches to approximately 56 inches. This would be the new point at which we would minimize the error (although our optimum error increases with the wider distribution). Yes, I realize that I have exaggerated the width of the distributions for effect.
Notice the effect on the crossover point. If the distribution of heights is greater for adults than for children (as it almost certain is), the cross-over point moves from 58 inches to approximately 56 inches. This would be the new point at which we would minimize the error (although our optimum error increases with the wider distribution). Yes, I realize that I have exaggerated the width of the distributions for effect.
Assumption 2: the number of children equals the number of adults in my population.
We can illustrate this by increasing the number of adults relative to the number of children.(Fellow bitheads: I did this by multiplying the adult pdf by 2. Obviously, it's no longer a valid pdf, but I think it's a valid way of calculating the appropriate decision point. Let me know.)
Once again, we see that the effect of doubling the number of adults relative to the number of children is to move the optimum decision point to the left, ie. around 56 inches instead of 58. One can even imagine a sufficiently large imbalance between adults and children at which the adult distribution completely absorbs the child distribution, and there is no non-zero decision height at which we could minimize our error. We would then decide that the entire population was adult.
Assumption 3: That the cost of my mistakes are equal.
Similar in effect to creating a population imbalance is to create an imbalance between the cost of mistaking a child for an adult vs the cost of mistaking an adult for a child. This is hard to illustrate with my made-up example, so let's look at a real-life example: testing for contagious diseases. Obviously, we want such tests to be as accurate as possible, but consider: if an AIDS test (routine screening, say) tells me I am sick when I am not actually sick, then I will begin unnecessary testing and treatment, but I will probably receive the correct diagnosis eventually, and will be out a lot of bother. However, if the test tells me that I am healthy when I am not, I will proceed to go home and infect my wife and, potentially, my family. In this illustration, the cost of making the second mistake greatly exceeds the cost of making the first. We would therefore want such errors as there are in AIDS testing to be "false positives" rather than "false negatives."
The point
This essay has a broad range of application to the use of statistics, but it's not really why I'm writing it. I was thinking about the assumption that many people will insist is fundamental to the use of statistics at all: the fundamental randomness of nature. Since the age of Newton, most people, and up until this century, most scientists, think of nature as fundamentally deterministic: a set of conditions and treatment {X} will always produce effect Y, or the relationship doesn't really exist. Scientists now understand that a valid relationship means that X will usually produce Y, but the randomness of nature implies that there are no metaphysically certain guarantees that this effect will always happen.
I'm using statistics a lot in my graduate work, yet I do not accept the premise that nature is fundamentally random. I will accept that it appears random, and therefore can be analyzed as such, because it is impossible to fully account for the full range of conditions under which we perform our experiments. But at a philosophical level, were it possible to so fully account for every input, then it would be possible to determine every output. And at a theological level, God hath foreordained whatsoever comes to pass.
This is not dissimilar to my take on evolution. Unsurprisingly, I reject the materialistic premise that many athiest tub-thumpers will insist is both a vital premise and an inexhorable conclusion of Darwinism. But somewhere along the line I decided I was comfortable applying the evolutionary paradigm anyway. It is highly probable, in my view, that the evolutionary process began by operating on the divinely created order, and produced the full extent of the variation we now see.
Note: I probably will not be blogging much this semester. My academic load has gone up, and my muse is underperforming.



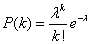 where “e” is an irrational number that equals approximately 2.718, and the exclamation point is the factorial function, where k! = k(k-1)(k-2)…(2)(1), all multiplied together. (Note: 0! = 1, for some strange reason.)
where “e” is an irrational number that equals approximately 2.718, and the exclamation point is the factorial function, where k! = k(k-1)(k-2)…(2)(1), all multiplied together. (Note: 0! = 1, for some strange reason.)  Because the factorial function is undefined for arguments less than zero, the summation is independent of indices less than zero. Thus:
Because the factorial function is undefined for arguments less than zero, the summation is independent of indices less than zero. Thus:  etc.
etc.
 As expected.
As expected.
 So, the variance of a Poisson distribution with average rate λ is . . . λ.
So, the variance of a Poisson distribution with average rate λ is . . . λ.


